
Maintainable and readable test code is crucial to establish a good test coverage which in turn enables implementing new features and performing refactorings without the fear of breaking something. This post contains many best practices that I collected over the years of writing unit tests and integration tests in Java. It involves modern technologies like JUnit5, AssertJ, Testcontainers, and Kotlin. Some recommendations might be obvious to you, but some might conflict with what you’ve read in books about software development and testing.

I’m using MongoDB in production for many years. In this time, I tried different tools and development approaches; some turned out to be useful for us, others don’t. In this post, I like to share handy CLI tools for working with MongoDB, a Docker-based local development approach and helpful Mongo shell snippets.
Since Vaadin 10, SASS is no longer supported out of the box. Fortunately, it’s really easy to integrate SASS in a Vaadin 10+ app and its Maven build. But how can we ensure a fast feedback cycle during the SASS development? Restarting the app is cumbersome. Even a page reload would reset the UI state, which leads to annoying clicking through the app. Luckily, there is an approach that automatically exchanges the changed CSS without any browser refresh or app restart.
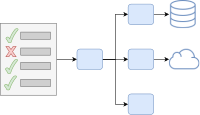
Testing classes in isolation and with mocks is popular. But those tests have drawbacks like painful refactorings and the untested integration of the real objects. Fortunately, it’s easy to write integration tests that hit all layers. This way, we are finally testing the behavior instead of the implementation. This post covers concrete code snippets, performance tips and technologies like Spring, JUnit5, Testcontainers, MockWebServer, and AssertJ for easily writing integration tests. Let’s discover integration tests as the sweet spot of testing.
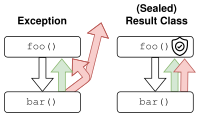
Exceptions are a common mean to handle errors. However, they have some drawbacks when it comes to compiler support, safety and traceability. Fortunately, we can leverage Kotlin’s sealed classes to create result objects that solve the mentioned problems. This way, we get great compiler support and the code becomes clean, less error-prone, easy to grasp and predictable.
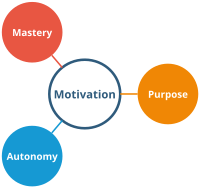
Motivation leads to higher performance and satisfaction in the job. But how can we motivate a team of software developers? Sadly, there are common misconceptions about motivation that do more harm than good. Fortunately, science has already discovered the motivators that work: autonomy, mastery, and purpose. This post presents these three pillars of motivation and concrete actions to implement them in software development environments.

On Oct 05, 2018, I held a talk about Best Practices for Unit Testing in Kotlin at the awesome KotlinConf in Amsterdam. I’m still overwhelmed by the packed room taking about 650 people. Thank so much for your interest! I’m also thrilled by the positive feedback on twitter. In this post, you can find the recording and the slides of my talk. The KotlinConf was an awesome conference. It was so great to meet the kind and open Kotlin community in person. Let’s carry on!

MongoDB’s dynamic schema is powerful and challenging at the same time. In Java, a common approach is to use an object-document mapper to make the schema explicit in the application layer. Kotlin takes this approach even further by providing additional safety and conciseness. This post shows how the development with MongoDB can benefit from Kotlin and which patterns turned out to be useful in practice. We’ll also cover best practices for coding and schema design.

Code reviews are powerful means to improve the code quality, establish best practices and to spread knowledge. However, code reviews can come to nothing or harm interpersonal relations when they are done wrong. Hence, it’s important to pay attention to the human aspects of code reviews. Code reviews require a certain mindset and phrasing techniques to be successful. This post provides both the author and the reviewer with a compass for navigating through a constructive, effective and respectful code review.

I just wanted to convert SVG to PNG files with Python and the library CairoSVG. That was no problem on my Ubuntu system. But running the SVG converter script within a lightweight Alpine Docker container turned out to be problematic. Figuring out which libraries have to be installed up front took me some time. That’s why I like to share my findings here. Hopefully, it’ll save your time.