Clean Code with Kotlin
Posted on Jun 25, 2017. Updated on Jun 12, 2022
With Kotlin we can write code that is easy to understand, short, expressive and safe. Sounds like clean code, doesn’t it? In this post, I go through some recommendations and principles of clean code and consider if Kotlin can help to fulfill this rules or not. Moreover, I show restrictions and points, where we should be careful. At the end, I discuss if Kotlin leads to “a dark or a bright path”.

Conference Talk
This post bases on my talk “Cleaner Code With Kotlin” (German) which I’ve given at the Clean Code Days in Munich in June 2017.
Recap: What is Clean Code?
Before we start, it’s important to recap what clean code is. First and foremost, clean code is code that is easy to understand. The code should be readable and intuitive. We can achieve this by making our code concise, short, simple and expressive. We are also facing clean code when it comes with minimal ceremony and syntactic noise.

What is clean code?
Clean Code and Kotlin

Let’s consider some rules and recommendations of Robert C. Martin’s popular book “Clean Code”. We’ll find out where Kotlin can help us to write clean code and where not. Let’s start with the items where I definitely see an improvement by using Kotlin. Afterward, I’ll talk about some restrictions and pitfalls.
Functions
Functions Should Be Small
“Rule 1: Functions should be small!
Rule 2: Functions should be smaller than that!”
Clean Codeby Robert C. Martin, page 34
According to clean code, functions should be small and they should do only one thing. We should extract subroutines and give them descriptive names. This way, our code becomes like a story. Moreover, we should separate details from the main logic. Can Kotlin help here? No, because these rules are language-agnostic. It’s still up to the developer to create small functions.
However, using Java, it’s sometimes tough to write small and expressive functions. Let me give you an example. Assume we want to map the payload of an HTTP response to an object and handle the error cases properly.
// Java
public Product parseProduct(Response response){
if (response == null){
throw new ClientException("Response is null");
}
int code = response.code();
if (code == 200 || code == 201){
return mapToDTO(response.body());
}
if (code >= 400 && code <= 499){
throw new ClientException("Sent an invalid request");
}
if (code >= 500 && code <= 599){
throw new ClientException("Server error");
}
throw new ClientException("Error. Code " + code);
}
Actually, there is not so much going on in the code. It just handles the error cases (null response and error HTTP status codes). It even doesn’t do the actual object mapping. Nevertheless, the code is quite verbose and contains a lot of syntactic noise. Contrary, take a look at the equivalent code in Kotlin.
// Kotlin
fun parseProduct(response: Response?) = when (response?.code()){
null -> throw ClientException("Response is null")
200, 201 -> mapToDTO(response.body())
in 400..499 -> throw ClientException("Sent an invalid request")
in 500..599 -> throw ClientException("Server error")
else -> throw ClientException("Error. Code ${response.code()}")
}
I claim that even if you don’t know every Kotlin feature used in this example, this code is very easy to understand. And that’s amazing! Being able to understand the code without knowing every feature, means that the code is definitely intuitive. That’s clean code! Using Kotlin, we can achieve the same logic with way less ceremony using fewer lines of code (15 vs 6 lines).
We see many cool Kotlin features here, which will be covered in detail later, but I want to point you to the when expression. Kotlin’s when is like Java’s switch statement but much more powerful. It’s more compact and you can check a variety of things in the cases (null, multiple values, ranges, types etc.).
This introduction example shows how Kotlin can help to reduce the syntactic noise and to keep functions small and expressive.
No Side-Effects
Clean Code tells us to reduce side-effects. We should not make unexpected and hidden changes that are not obvious when looking at the function name.
But what is the problem with side-effects at all? Code with side-effects is error-prone, hard to understand, hard to test, hard to parallelize (not thread-safe), not cacheable and can’t be evaluated lazily. We can avoid side-effects with concepts from functional programming. This basically means to write pure functions (= functions without side-effects).
Kotlin comes in handy here because it has way better support for functional programming than Java has:
- Expressions
- Immutability
- Function Types
- Concise Lambda Expressions
- Kotlin’s Collection API
However, it should be noted, that Kotlin’s functional capabilities can’t be compared with Haskel or even Scala.
Expressions
Flow Control Structures Are Expressions
In Kotlin, flow control structures are expressions and not statements. We already saw the when expression in action. But also if-else and try-catch are expressions in Kotlin. This is pretty handy:
val json = """{"message": "HELLO"}"""
val message = try {
JSONObject(json).getString("message")
} catch (ex: JSONException) {
json
}
In Java, we have to declare the variable message before the try in a separate line. Moreover, the message can’t be mutable (final). Using Kotlin’s try expression, we can save a line and make message immutable (val). A workaround in Java would be to extract the try to a subroutine. Although we can give this routine a nice descriptive name, sometimes that is over-the-top.
Single Expression Function
Another neat feature are single expression functions. If a function contains only a single expression, we can leave out the curly braces {} and the return type.
fun getMessage(json: String): String {
val message = try {
JSONObject(json).getString("message")
} catch (ex: JSONException) {
json
}
return message
}
// becomes:
fun getMessage(json: String) = try {
JSONObject(json).getString("message")
} catch (ex: JSONException) {
json
}
The single expression function is much more compact: The essential logic is revealed immediately due to the reduced syntactic noise. As we see, Kotlin’s expression support allows us to combine control structures with other expressions concisely.
Be Aware of Train Wrecks
It’s tempting to squeeze everything into a single expression. Just because you can do this, doesn’t mean that it’s a good idea. Developer’s discipline and awareness for readable and clean code are especially important at this point.
// You don't have to read this line by line :-)
// Don't:
fun map(dto: OrderDTO, authData: RequestAuthData) = OrderEntity(
id = dto.id,
shopId = try {
extractItemIds(dto.orderItems[0].element.href).shopId
} catch (e: BatchOrderProcessingException) {
restExc("Couldn't retrieve shop id from first order item: ${e.msg}")
},
batchState = BatchState.RECEIVED,
orderData = OrderDataEntity(
orderItems = dto.orderItems.map { dto -> mapToEntity(dto) },
shippingType = dto.shipping.shippingType.id,
address = mapToEntity(dto.shipping.address),
correlationOrderId = dto.correlation?.partner?.orderId,
externalInvoiceData = dto.externalInvoiceData?.let { ExternalInvoiceDataEntity(
url = it.url,
total = it.total,
currencyId = it.currency.id
)}
),
partnerUserId = authData.sessionOwnerId ?: restExc("No sessionId supplied", 401),
apiKey = authData.apiKey,
dateCreated = if (dto.dateCreated != null) dto.dateCreated else Instant.now(),
)
When in doubt prefer temporary variables and subroutines. It shouldn’t be our aim to use expressions but to create readable code. Sometimes, this can coincide but it doesn’t have to.
Readability beats Squeezing everything into a single line
Immutability
Utilizing immutability in Kotlin feels natural and easy. In fact, it’s the idiomatic way of coding in Kotlin. This way, Kotlin encourages using immutable variables, data structures and collections. This, in turn, makes your code safer and easier to understand.
Immutable References
In Kotlin, we should always use val to declare a variable. This creates an immutable variable. In Java, we have to add the additional keyword final (again, syntactic noise!). If your variable really has to be mutable, you can use var. But think twice before you use var.
val id = 1
id = 2 // compile error!
var id2 = 1
id2 = 2
Read-Only Collections
The idiomatic way of creating a list in Kotlin is the method listOf(). This creates a read-only list, so you can’t add any elements to it. Note that Kotlin’s collections are not immutable because they base on Java’s mutable collection for interoperability reasons. But in practice, this is good enough most of the time.
val list = listOf(1,2,3,4)
list.add(1) //compile error. This method doesn't exist in the read-only interface of Kotlin's list.
Kotlin’s collection API also returns a new read-only list. The original list is not changed.
val evenList = list.filter { it % 2 == 0 }
Please also note the compact API and lambda syntax. We can invoke the filter() method directly on the list (no stream() like in Java 8 required). Besides filter() already returns a new list (no collect(Collectors.toList()) required). Finally, we can see a very compact lambda notation: We can leave out the parenthesis (), if there is only one parameter and the parameter is a lambda. Furthermore, we can leave out the parameter declaration in the lambda, if there is only one parameter. In this case, we can refer to the parameter using it. In this case, it’s obvious what it refers to. In other cases, it may be better to declare the parameter explicitly with a descriptive name. All in all, the collections API requires way less ceremony and boilerplate.
Immutable Data Classes
It’s so easy to create immutable data structures in Kotlin with data classes. In fact, this is a killer feature of Kotlin. In Java, we need a huge amount of boilerplate and ceremony to create an immutable class properly: We need backing final fields, getter, constructors (assigning the parameters to the corresponding fields), hashCode(), equals(), toString() and mark the class with final. In Kotlin, we can utilize data classes:
data class DesignData(
val id: Int,
val fileName: String,
val uploaderId: Int,
val width: Int = 0,
val height: Int = 0
)
That’s it! The code mainly consists of the essential parts: The class name and the property definitions with minimal ceremony. We have to type, read and maintain less code!
Moreover, Kotlin supports default arguments (see val width: Int = 0). This makes the verbose and annoying constructor chaining to simulate default arguments obsolete.
But things are getting even better when it comes to the constructor invocation.
val design = DesignData(id = 1, fileName = "cat.jpg", uploaderId = 2)
First, we don’t need the useless new keyword anymore. Second, Kotlin supports named arguments, which significantly increases the readability and safety of the code. We can’t accidentally mix up arguments of the same type anymore.
Furthermore, we can access the properties via the short property access syntax. No need to call a getter.
val id = design.id
design.id = 2 //compile error. Immutable property.
The copy() method is especially handy in the context of functional programming. As all data structures should be immutable, we need means to easily create a copy of an object. Besides, copy() allows passing arguments for the property that should be changed. All other properties remain unchanged and are simply copied.
val design2 = design.copy(fileName = "dog.jpg")
Error Handling
Let’s analyze if Kotlin can help when it comes to the Clean Code recommendations regarding error handling.
| Clean Code Recommendation | Kotlin Support? |
|---|---|
| Separate error handling from logic | No |
| Don’t use checked exceptions | Checked exceptions don’t exist |
Use strategies to avoid null(exceptions, empty collection, null object, special case object) |
No |
Don’t return null. Reasons: |
No |
a) Scattered code with null-checks |
Concise syntax for dealing with null |
b) Easy to forget null-check. NPE. |
Nullable types. The compiler enforces handling. |
As we see, most of the recommendations are language-independent. I only want to point to the last three lines. Even with Kotlin, it’s still up to the developer to avoid returning null. But let’s face the reality: null values and NullPointerExceptions will always occur in our code. That’s a fact. So we have to handle them. Fortunately, Kotlin supports powerful means to deal with null. Let’s take a look at them.
Nullable and Non-Null Types
The null-aware type system is another killer feature of Kotlin. Kotlin extends Java’s type system. First of all, the compiler knows the type of a variable (String, Int, Date) and therefore the methods that we can call on an object. But Kotlin’s type system goes further. Additionally, we can mark a type as nullable (can be null) or non-null (can’t be null). A nullable type provides different methods than its non-null counterpart which can be checked by the compiler.

val value: String = "Clean Code"
val value: String = null // compile error! Can't assign null to non-null type.
val nullableValue: String? = "Clean Code"
val nullableValue: String? = null
val value: String = nullableValue // compile error! Can't assign nullable value to non-null value.
To assign a nullable value to a non-null value we have to add a null-check:
val value: String = if (nullableValue == null) "default" else nullableValue // smart-cast of nullableValue
This compiles successfully. The compiler detects the null-check and casts nullableValue to the non-null type. This automatic cast is called “smart-cast” and makes explicit casts in several cases obsolete (again, less ceremony!). But we can make the above line even shorter by using the elvis operator ?::
val value: String = nullableValue ?: "default"
If the left side of the elvis operator (nullableValue) is not null, the whole expression evaluates to the value of nullableValue, which is assigned to the variable (value). If the left side is null the right side (“default” String) is assigned.
Nullability in Action
Let’s assume a nested domain hierarchy: An order has a customer which has an address which has, in turn, a city. Now, we want to drill through the hierarchy to retrieve the city. That’s a quite common use case. However, every element in the chain can be null and are therefore nullable typed. Hence, the following code doesn’t compile:
val city = order.customer.address.city // compile error! order, customer and address can be null!
The compiler doesn’t allow us to call the customer property on order because the order can be null and we didn’t handle this case. The compiler points us to this possible errors at compile time. This significantly reduces errors and increases the safety.
So what can we do instead? There are several options. Option 1 is to use the not-null assertion !!.
val city = order!!.customer!!.address!!.city // avoid this!
This satisfies the compiler. But a NullPointerException is thrown, when one element in the chain is null. Let’s strive for a better way.
Option 2 is Java-style: Use several if-null-checks:
if (order == null || order.customer == null || order.customer.address == null){
throw IllegalArgumentException("Invalid Order")
}
val city = order.customer.address.city // smart-cast
This approach works but is annoying. It’s verbose and error-prone because it’s easy to forget a null-check. By the way, after the checks the compiler allows the access via . since it detects the previous null-checks.
Option 3: But we can do better. This is where the safe call operator ?. enters the stage. It executes a call only when the invocation target is not null. Otherwise, the whole expression is null.
val city = order?.customer?.address?.city
So city becomes null if any element in the chain is null. Very handy. However, we want to throw an exception in the case of null. The elvis operator is extremely useful here:
val city = order?.customer?.address?.city ?: throw IllegalArgumentException("Invalid Order")
If any element in the chain is null, an exception will be thrown. The combination of safe calls and the elvis operator is a very powerful idiom in Kotlin. It allows dealing very concisely with null values.
To wrap up, the nullability in Kotlin’s type system makes our code safer and less error-prone. This is achieved by adding only a few syntax constructs to the code (e.g. ? behind the type). For me, the safety-typing ratio is very good. In return, Kotlin supports compact and expressive means for null handling. They remove a lot of syntactic noise and ceremony and finally lead to more readable code.
Less Ceremony
Reduced Syntactical Noise
Compared to Java, Kotlin reduces the syntactical noise and is more expressive.
- No
newkeyword required to call a constructor. - No semicolon required.
- Types can be inferred. No need to write them down. Just write
val. - Often, no explicit cast is required (smart-casts)
- No escaping required in triple-quoted strings.
The following table is taken from the book Kotlin in Action
by Dmitry Jemerov and Svetlana Isakova (table 11.1, page 283).
| Regular Syntax | Clean Syntax | Feature in Use |
|---|---|---|
StringUtil.capitalize(s) |
s.capitalize() |
Extension function |
1.to("one") |
1 to "one" |
Infix call |
set.add(2) |
set += 2 |
Operator Overloading |
map.get("key") |
map["key"] |
Convention for the get method |
file.use({ f -> f.read() }) |
file.use { it.read() } |
Lambda outside of parentheses |
sb.append("yes")sb.append("no") |
with(sb) {append("yes")append("no")} |
Lambda with a receiver |
Especially extension functions can make your code expressive and cleaner. But be careful with operator overloading. It can lead to clean but also to bad code. Only use it, when the meaning of the operator is intuitive (like + with numbers, strings and dates). In other cases, prefer a method call with a descriptive and intention-revealing name.
Popular Java Idioms and Patterns are Built-in
There are many idioms and patterns in Java that require quite a lot of boilerplate code. For instance, implementing the Singleton, Observer or Delegation pattern is quite verbose in Java. Often they only bypass the shortcomings of the Java language. Fortunately, many of those patterns and idioms are built-in right into Kotlin. Check out my blog post about Idiomatic Kotlin for further details.
Restrictions
Good Design Leads to Clean Code
Until now, we only considered Functions and Error Handling with Kotlin. Beyond that, I see improvements with Kotlin when it comes to Objects and Data Structures (via data classes) and Concurrency (Kotlin 1.1’s coroutines). But Martin’s book Clean Code
covers more topics:
- Meaningful Names
- Functions
- Comments
- Formatting
- Object and Data Structures
- Error Handling
- Boundaries
- Classes
- Systems
- Emergence
- Concurrency
What about naming? Names should be intention-revealing. But that’s independent of the used language. Same goes for comments, formatting, boundaries, class design and so on. As we see, good software design is still extremely important for writing clean code and is independent of the used language. Just think about proper data abstraction, small classes, law of demeter, wrapping boundaries, single responsibility principle, information hiding etc. The used language is only one aspect on the way to clean code. To emphasis this point, I went through Chapter 17 “Smells and Heuristics” of Martin’s “Clean Code” and analyzed if Kotlin can help avoiding each smell.
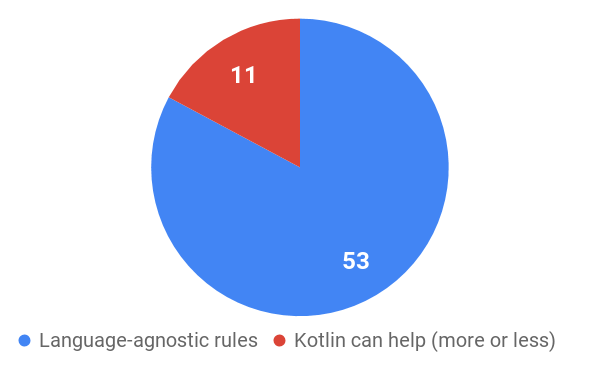
Most of the smells and heuristics in the book ‘Clean Code’ are language-independent in my opinion.
To my mind, most of the rules are language-independent. Many of them concern the (object-oriented) design. So following these rules is still up to the developer and his feeling for clean code.
Feature Obsession
Just because there is a feature, doesn’t mean that you should use it in every case. Especially be careful with:
- Unreadable monster expressions (see section Be Aware of Train Wrecks)
- Complicated safe calls and elvis structures
Let me give you an example for the last point. Let’s assume we want to put a nullable string in a map only if the string is not null and not empty. Sounds simple, right? Look at the following approach:
// Don't
value?.emptyToNull()?.let { map.put("bla", it) } // uh, "it" is smart-casted.
// Helper method required:
fun String.emptyToNull() = if (this.isEmpty()) null else this
The obessions to get along with a single expression and to utilize smart-casts (avoiding not-null assertions) can lead to pretty unreadable code. Another approach:
// Don't
if (value?.isNotEmpty() ?: false){
map.put("key", value!!)
}
Even worse. Especially when beginning to learn Kotlin it’s easy to get lost in complex constructs with safe calls, elvis operators and expressions. In this cases, it’s good to remember the good old if-null-or-empty-statement.
// KISS!
if (!value.isNullOrEmpty()){
map.put("key", value!!)
}
Yes, there is a not-null assertion !! because the compiler doesn’t detect the null check in the method isNullorEmpty(). But this code is extremely readable and clean!
Readability and Simplicity are (still) King!
It’s totally fine to don’t use some features. Readability and simplicity are more important than using Kotlin’s fancy features every time.
Conclusion
Can we write cleaner code with Kotlin? Yes, definitely! The reasons are the following:
- Increased readability due to less boilerplate and syntactic noise
- Increased safety
- Kotlin encourages good design
But there are two things to keep in mind:
- Clean code and good design are no automatism with Kotlin. The developer’s discipline is still important.
- Use some features with sound judgment. Sometimes the “old” means are the better choice. Always remember that clarity is king.
Epilog: The Bright Path
Way back when I started my career as a professional software developer, Uncle Bob’s book “Clean Code” inspired me and changed the way I write code. But I couldn’t disagree more with his post “The Dark Path” where he criticizes Kotlin (and Swift). In fact, I’m disappointed. That’s why I like to put my two cents in:
- Classes and methods are final by default: Yes, this design decision is hotly disputed in the community. But for me, this is not a big issue in daily work.
- Null-Safety: This is one of my personal killer features of Kotlin! Let’s be honest: Making mistakes is human. So developers will always make mistakes. It’s inevitable. Thus it’s great that Kotlin helps the developer by pointing him to potential mistakes (NullPointerExceptions). But this doesn’t mean that we should be thoughtless and stop writing tests. It’s just an additional layer of safety. I can’t see why this is bad at all; especially when it comes with such minimal additional syntax.
“Making a car safer doesn’t mean you should drive careless.” sebaslogen
By the way, at the Google I/O 2017 the Android team announced that Kotlin is now an official language for Android development. So there are so many folks out there (not only at Google) appreciating Kotlin and its features.
In this post, I tried to point out that Kotlin provides a huge amount of great features that let you write cleaner code. So even if you don’t like the two mentioned design decisions, you still have to concede that Kotlin code is basically more readable, intuitive, expressive and safe. Isn’t that what clean code is all about? Hence, Kotlin is definitely a step forward - on “The Bright Path”.
Further Reading
- I highly recommend the book Kotlin in Action
by Dmitry Jemerov and Svetlana Isakova
- Book Clean Code